




Ce site utilise des cookies afin que nous puissions vous fournir la meilleure expérience utilisateur possible. Les informations sur les cookies sont stockées dans votre navigateur et remplissent des fonctions telles que vous reconnaître lorsque vous revenez sur notre site Web et aider notre équipe à comprendre les sections du site que vous trouvez les plus intéressantes et utiles.

Catégorie:
Intelligence Artificielle
Branche:
Santé
Ville:
Oklahoma, États-Unis
Client
Le client est une entreprise américaine du secteur de la santé qui traite quotidiennement un grand volume de documents financiers, tels que des confirmations de paiement ou des relevés d’assurance. La majorité de ses processus opérationnels est automatisée et repose sur l’échange de documents électroniques structurés (comme le format EDIFACT), garantissant une communication fluide et une efficacité élevée. Toutefois, un défi persistant concernait les documents non structurés – scans, impressions papier, fichiers au format image – nécessitant un traitement manuel, ce qui limitait la scalabilité et sollicitait fortement les ressources humaines.
Défi
L’objectif principal était d’automatiser la séparation et la classification de documents papier ou numérisés contenant plusieurs pages. La solution devait être capable de gérer les bruits (ex. : pages non pertinentes, scans mal orientés, mises en page variables), tout en assurant une grande précision dans la détection des limites des documents et leur catégorisation. Cela nécessitait des capacités avancées en traitement d’image et de texte, ainsi qu’une adaptation aux processus métiers spécifiques du client.

Solution
Le projet a été mené en plusieurs étapes, combinant l’exploration des données, le développement de modèles de machine learning (ML) et l’intégration de règles adaptées aux besoins métier du client.
La solution développée comprenait :
- Des modèles de détection des frontières de documents dans un flux de pages, basés sur une classification binaire de paires de pages – le système compare les pages adjacentes pour déterminer si elles appartiennent au même document. Cela permet de segmenter automatiquement un lot de pages en documents distincts.
- Des classificateurs pour affecter les documents aux bonnes catégories, facilitant leur traitement rapide par les départements appropriés – par exemple, les factures vers la comptabilité, les formulaires vers la facturation. Cette étape élimine le tri manuel et les retards associés.
- Le fine-tuning de modèles de type transformer, des algorithmes avancés capables de comprendre la mise en page et le contenu des documents de manière proche de l’humain (Document AI). L’adaptation à la donnée métier du client a permis d’accroître considérablement la précision.
- La définition de règles de post-traitement permettant d’adapter les résultats du modèle aux besoins concrets de l’entreprise. Exemple : si un document ne contient pas un numéro de référence requis, il sera signalé pour révision manuelle, même s’il est jugé valide par le modèle.
Le projet comprenait également :
- L’analyse exploratoire des données (EDA) et leur évaluation qualitative,
- Le filtrage de pages contenant du bruit ou des informations non pertinentes,
- Le développement et le test des modèles de séparation et de classification,
- L’intégration de ces modèles dans une application métier existante du client.
Ensemble, ces composants constituent un système flexible qui identifie, classe et facilite le traitement des documents en accord avec les processus établis.
Résultats
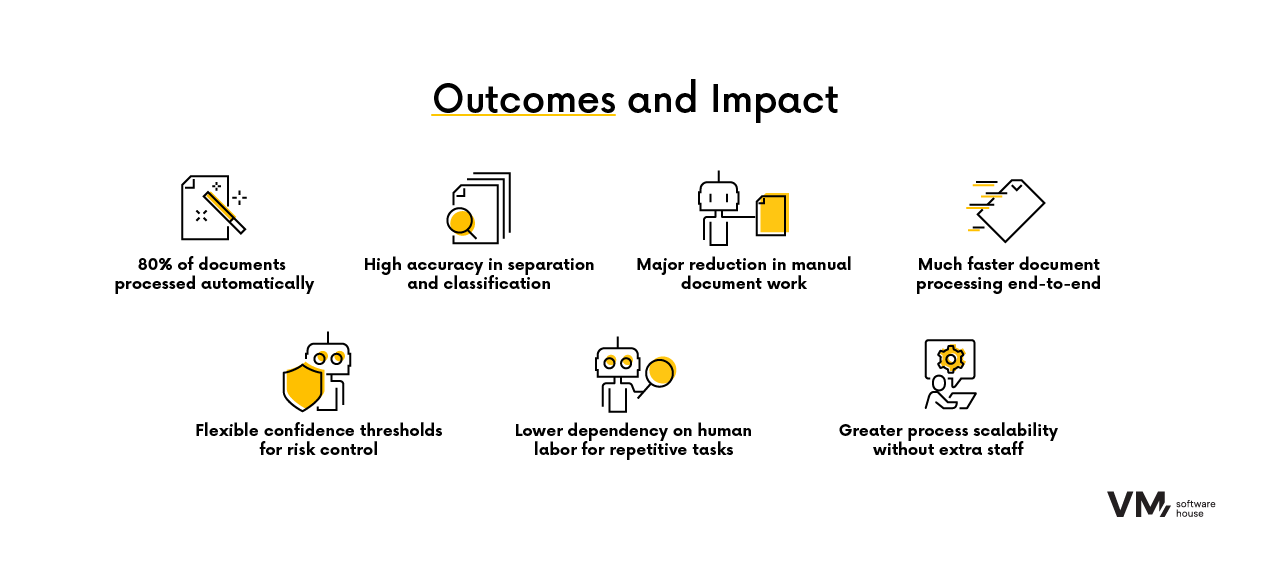
Grâce à cette solution, le client a obtenu des améliorations significatives :
- Plus de 80 % des documents ont été traités sans intervention humaine,
- Des taux de précision élevés pour la classification et la détection des documents,
- Une réduction notable du temps et des ressources humaines nécessaires au traitement manuel,
- La mise en place de seuils de confiance ajustables, pour adapter le niveau d’automatisation au niveau de risque opérationnel.
Impacts métier :
- Meilleure scalabilité sans augmentation proportionnelle des effectifs,
- Traitement accéléré des documents et transactions plus fluides,
- Réduction de la dépendance au travail manuel pour les tâches chronophages.
Technologies
La solution s’appuie sur les dernières avancées en traitement documentaire et en intégration de données multimodales :
- Utilisation combinée de OCR, boîtes de délimitation du texte (bounding boxes) et scans graphiques,
- Agrégation d’embeddings de page avec pooling, couches d’attention et réseaux Bi-LSTM,
- Séparation des documents par classification binaire de paires de pages,
- Fine-tuning de modèles transformer pour le secteur de la santé.
La solution a été entièrement alignée sur les processus métiers du client, ce qui la rend reproductible dans d’autres secteurs comme la logistique ou l’administration, où la documentation papier reste dominante.

Optimisation de la consommation d’énergie avec des modèles prédictifs et des algorithmes d’IA
Conception, développement, DevOps ou Cloud - de quelle équipe avez-vous besoin pour accélérer le travail sur vos projets ?
Discutez avec vos partenaires de consultation pour voir si nous sommes compatibles.
Jakub Orczyk
Membre du Conseil d’administration/Directeur des ventes VM.PL
Réservez une consultation gratuite