


Dans cet article, nous nous concentrerons sur les algorithmes de ML de base. Nous discuterons de leurs types, de leur fonctionnement et des étapes nécessaires à la création et à l’entrainement de vos propres modèles.
Sommaire
Qu’est-ce qu’un algorithme d’apprentissage automatique ?
Les algorithmes d’apprentissage automatique sont des modèles mathématiques formés à partir de données. Ils utilisent des techniques statistiques et d’analyse prédictive dans l’analyse des données pour apprendre des modèles et des relations entre les données. Ils utilisent ensuite ces connaissances pour faire des prédictions ou prendre des mesures sur des données nouvelles et non testées.
Leur principal avantage réside dans leur capacité à traiter les données d’entrainement sous de nouvelles formes, inconnues auparavant, ce qui leur permet de faire des prédictions précises dans des scénarios réels.
Critères de sélection des algorithmes
Le choix d’un algorithme dépend de nombreuses variables. Même les data scientists les plus expérimentés ne peuvent pas déterminer le meilleur algorithme avant de l’avoir testé sur un ensemble de données précises.
Par conséquent, le choix relève largement de la spéculation si l’on ne teste pas d’abord plusieurs algorithmes sur un ensemble défini de données. Toutefois, il existe un ensemble de règles qui, sur la base de plusieurs variables, vous aident à restreindre votre recherche aux 2 ou 3 algorithmes les mieux adaptés à votre cas particulier. Vous pouvez tester les algorithmes indiqués sur un ensemble de données réelles afin que la prise de décision soit une formalité.
- Type de tâche
Nous ajustons généralement les méthodes, en commençant par les plus simples, pour confirmer qu’il est judicieux de passer à des algorithmes plus profonds et plus complexes. Tout d’abord, nous analysons le type de tâche sur lequel nous travaillons ; par exemple, s’agit-il d’une tâche de classification dans laquelle nous voulons prédire des catégories spécifiques ? Ou s’agit-il d’une tâche de régression dans laquelle on veut prédire des valeurs continues ? Mieux nous comprenons la nature de la tâche, plus le choix d’un algorithme spécifique sera précis.
- Taille et type de données
La compréhension des données est la clé du succès. C’est pourquoi nous analysons toujours les données spécifiques que nous traitons ; les bonnes données fournissent les informations dont nous avons besoin. L’analyse exploratoire des données est toujours la première étape d’un projet.
La compréhension des données est également utile aux étapes intermédiaires :
– Avant de procéder au nettoyage des données, nous collectons des informations sur les valeurs manquantes.
– Avant de commencer à transformer les données, nous devons savoir quel type de variables se trouve dans l’ensemble.
– Avant de commencer le processus de modélisation, nous vérifions les observations aberrantes et les variables ayant des distributions inhabituelles dans l’ensemble.

Certains algorithmes sont mieux adaptés aux petits ensembles de données, tandis que d’autres peuvent traiter efficacement de grands ensembles de données et des relations complexes entre les variables.
Si vous disposez d’un petit ensemble de données avec une relation simple entre les variables, des algorithmes tels que la régression linéaire ou la régression logistique peuvent être suffisants. Si vous disposez d’un vaste ensemble de données avec des relations complexes, des algorithmes tels que les forêts aléatoires ou les machines à vecteurs de support peuvent être plus appropriés.
- Interprétation ou performance
Un autre facteur à prendre en compte est le compromis entre l’interprétabilité et l’efficacité. Certains algorithmes, tels que les arbres de décision, permettent l’interprétation et fournissent des explications claires sur leurs prédictions. D’autres algorithmes, tels que les réseaux neuronaux, peuvent être plus performants, mais manquent d’interprétabilité.
Si l’interprétabilité est essentielle à votre projet, les algorithmes tels que les arbres de décision ou la régression logistique sont de bons choix. Si la performance est l’objectif principal et que l’interprétabilité n’est pas une priorité, les réseaux neuronaux ou les modèles d’apprentissage profond peuvent être plus appropriés.
- La complexité de l’algorithme
La complexité de l’algorithme est également un facteur essentiel. Certains algorithmes sont relativement simples et faciles à mettre en œuvre, tandis que d’autres sont plus complexes et nécessitent des compétences de programmation ou des ressources informatiques avancées.
Si vos compétences en programmation sont limitées, des algorithmes tels que la régression linéaire ou les arbres de décision constituent un bon point de départ. Si vous disposez de compétences en programmation et de ressources informatiques plus avancées, vous pouvez explorer des algorithmes plus complexes, tels que les réseaux neuronaux ou les modèles DL.
Compte tenu de ces facteurs, vous pouvez réduire vos options et choisir l’algorithme d’apprentissage automatique qui convient à votre projet. Il est important d’expérimenter différents algorithmes et d’évaluer leurs performances pour votre tâche et vos données précises.
Division des algorithmes dans l’apprentissage automatique
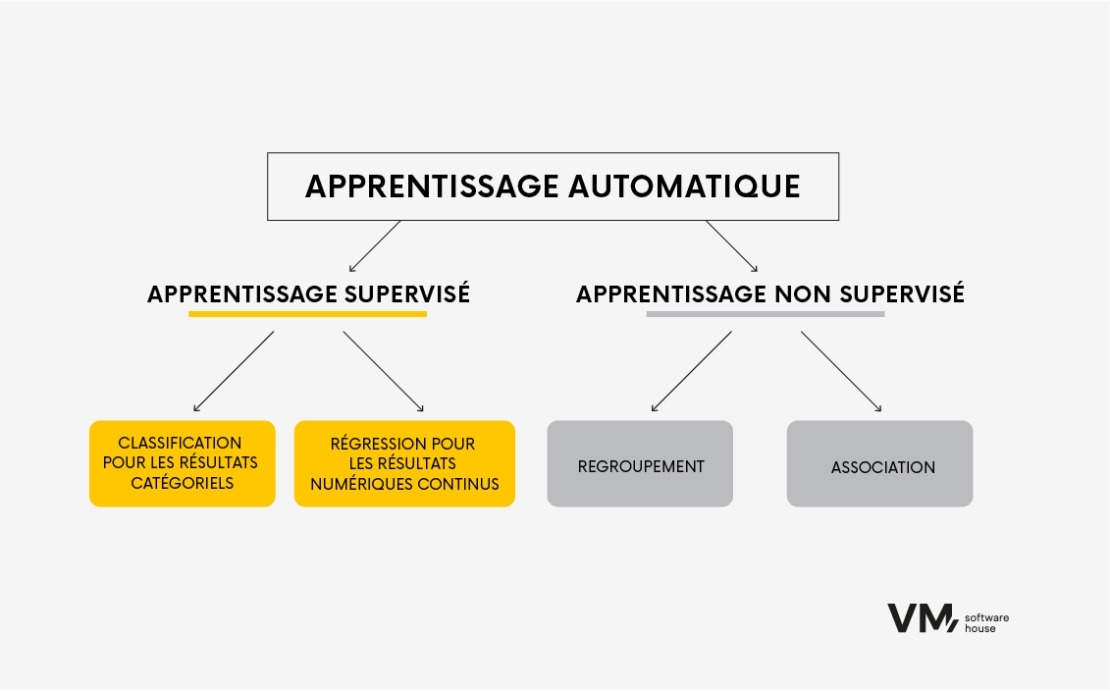
La manière la plus générale de diviser les algorithmes est basée sur le type d’apprentissage : supervisé et non supervisé.
Apprentissage supervisé
Les algorithmes d’apprentissage supervisé sont formés sur des données étiquetées, où les données d’entrée sont associées à la sortie correcte ou à la variable cible. L’algorithme apprend à affecter les données d’entrée aux données de sortie appropriées en trouvant des modèles et des relations dans les données. Ce type d’algorithme est couramment utilisé dans des tâches telles que la classification et la régression.
Nous utilisons des algorithmes, par exemple la régression, pour prédire une valeur numérique sur la base des caractéristiques de sortie. Cette valeur peut être, par exemple, la solvabilité estimée, le risque de fraude pour une transaction sélectionnée ou une valeur binaire indiquant si un client bancaire donné sera un bon ou un mauvais emprunteur. En résumé, dans ce cas, nous savons exactement ce que nous recherchons et sur quoi nous baserons nos décisions.
Un exemple serait un ensemble de données sur les clients d’une banque, décrit par des variables telles que la date de naissance, le numéro d’identification, le solde du compte, l’adresse du domicile, les données sur les antécédents de crédit, l’historique des transactions, etc.
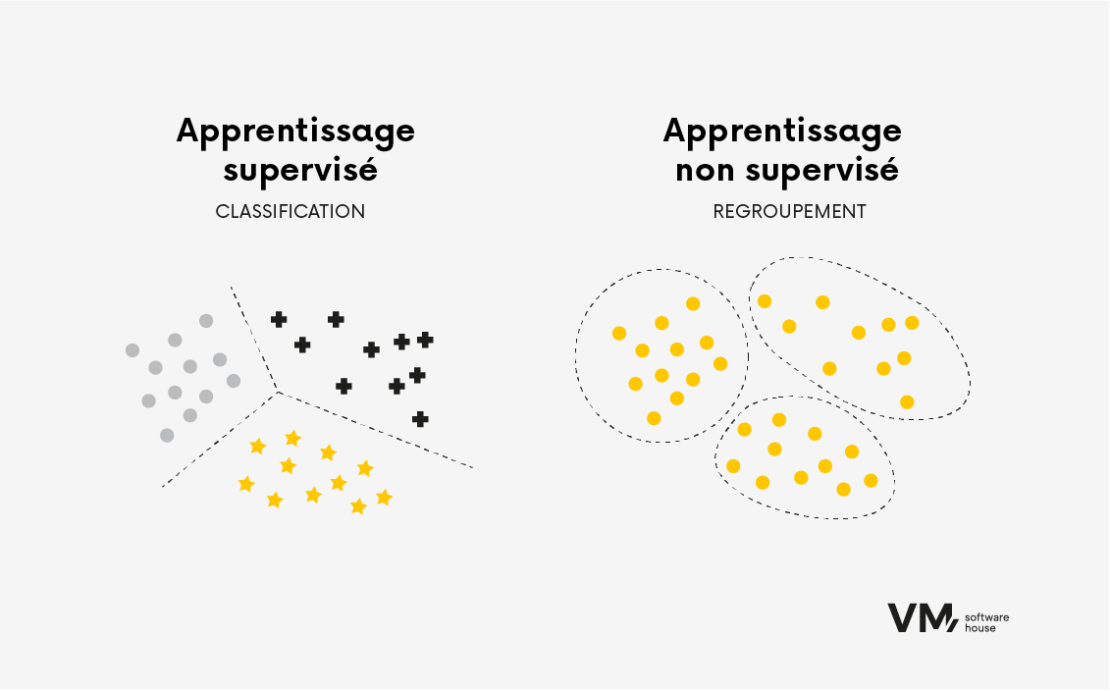
Apprentissage non supervisé
Les algorithmes d’apprentissage non supervisé sont formés sur des données non étiquetées, dans lesquelles seules les données d’entrée sont disponibles sans étiquette de sortie ou de cible correspondante. L’objectif de l’apprentissage non supervisé est de découvrir des modèles ou des structures cachés dans les données. Les algorithmes d’apprentissage non supervisé sont utiles lorsque la structure sous-jacente des données est inconnue.
Nous utilisons souvent des algorithmes de ce type dans des tâches telles que le regroupement et la réduction de la dimensionnalité. Par exemple, l’algorithme regroupe des points de données similaires dans les tâches de regroupement en fonction de leurs similitudes internes. Cela peut être utile dans des tâches telles que la segmentation de la clientèle, où l’algorithme peut identifier des groupes de clients ayant des préférences ou des comportements similaires.
Algorithmes populaires d’apprentissage automatique
Les algorithmes d’apprentissage automatique se présentent sous de nombreuses formes et formats, chacun ayant des caractéristiques uniques. Dans cette section, nous examinerons quelques algorithmes populaires et leurs applications dans divers secteurs.
- Classification binaire
Dans les tâches de classification, l’algorithme apprend à classer les données d’entrée dans deux catégories ou classes prédéfinies.
La classification est utilisée dans des situations telles que la détection d’objets, toutes sortes d’automatisation, le comptage d’objets, mais aussi, par exemple, dans le domaine médical, comme la détection de divers changements dans l’imagerie médicale, par exemple, lorsque nous voulons distinguer une personne malade d’une personne en bonne santé.
La classification binaire implique la formation d’un algorithme pour affecter les données d’entrée à deux catégories ou classes prédéterminées. Par exemple, un algorithme d’apprentissage supervisé peut être entrainé à déterminer si un courriel est un pourriel ou non en analysant un ensemble de données de courriels étiquetés. La classification binaire est couramment utilisée lorsqu’il s’agit de passer au crible un ensemble de données donné et de séparer deux groupes.
À quelles questions les algorithmes de classification répondent-ils ? Par exemple :
- Le client sera-t-il un bon emprunteur ? (remboursera-t-il le prêt en totalité, sans retard significatif ?) | 0,1 (oui ou non).
- Un client donné voudra-t-il annuler nos services ? | Le taux de résiliation est de 0,1 (oui ou non).
- La transaction est-elle frauduleuse ? | 0,1 (oui ou non).
- Classification multiclasses
La classification multiclasses consiste à essayer de prédire un résultat unique, comme dans la classification binaire, mais avec plus de deux classes. Parfois, nous voulons différencier quelque chose d’un peu plus compliqué. Dans le cas de la distinction des maladies, par exemple, nous voulons savoir de quel grade de cancer il s’agit, à quel stade il se trouve, ou déterminer un type spécifique de cancer parmi d’autres types.

Dans l’image ci-dessus, nous voyons l’application d’algorithmes sous supervision. Les méthodes utilisées sont les suivantes :
- CLASSIFICATION – à l’aide de la classification, nous pouvons dire que dans l’image, il y a un chien, des jouets en peluche et une tasse.
- DÉCOUVERTE D’OBJET – nous voulons trouver une tasse particulière pour un chien. Grâce à cette méthode, nous déterminerons les limites de l’objet (rectangle) et la probabilité que cet objet spécifique se trouve dans le cadre.
- SEGMENTATION – une méthode qui tente de trouver et de marquer des objets individuels aussi précisément que possible, en les séparant les uns des autres. SEGMENTATION SÉMANTIQUE – une méthode qui marque un objet des objets du même type.
- Régression linéaire
La régression linéaire est une équation linéaire qui détermine la relation entre différentes dimensions.
L’algorithme apprend à trouver la ligne la mieux ajustée qui minimise la somme des erreurs quadratiques entre les valeurs prédites et les valeurs réelles. Il est souvent utilisé dans la prédiction numérique. Par exemple, un algorithme qui peut prédire la valeur d’une maison en fonction de caractéristiques telles que son emplacement, le nombre de chambres et la superficie.
La régression linéaire est largement utilisée en finance, en économie et en sciences sociales pour analyser les relations entre les variables et faire des prédictions. Par exemple, elle peut être utilisée pour prédire les prix des actions sur la base de données historiques.
- Régression logistique
La régression logistique est un algorithme populaire permettant de prédire un résultat binaire, tel que « oui » ou « non », sur la base d’observations précédentes de l’ensemble des données.
Détermine la relation entre une variable dépendante binaire et une ou plusieurs variables indépendantes en ajustant une fonction logistique aux données. L’algorithme apprend à trouver la courbe la mieux adaptée qui sépare deux classes.
La régression logistique est largement utilisée dans les domaines du marketing, de la santé et des sciences sociales pour prédire le taux de désabonnement, détecter les fraudes et diagnostiquer les maladies. Par exemple, elle peut être utilisée pour indiquer si un client est susceptible d’abandonner un achat sur la base de son comportement passé ou pour diagnostiquer si un patient est atteint d’une maladie particulière sur la base de ses symptômes et de ses antécédents médicaux.
- Arbres de décision
Les arbres de décision sont des algorithmes polyvalents qui peuvent être utilisés pour des tâches de classification et de régression. Ils divisent les données en sous-ensembles sur la base des valeurs des caractéristiques d’entrée et effectuent des prédictions en parcourant l’arbre de la racine à la feuille. L’avantage des arbres réside dans l’interprétabilité des résultats de la prédiction.
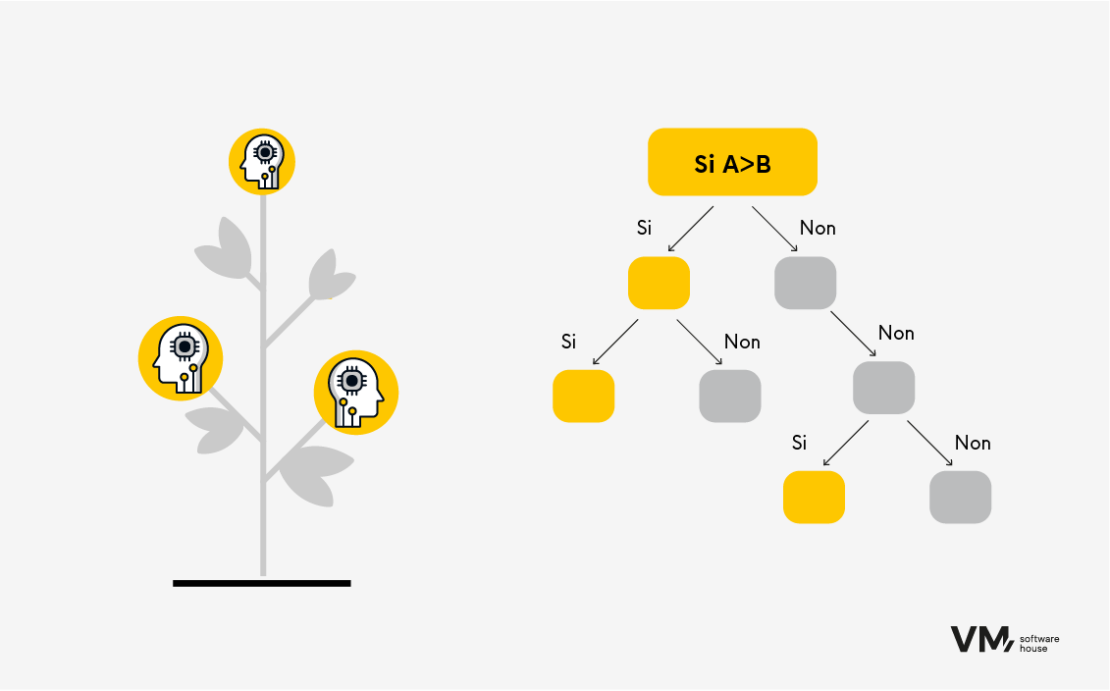
Exemple :
Vous avez les résultats des tests. Vous voulez en savoir plus :
- Séparation des sexes : femme ou homme ? Êtes-vous une femme ? Consultez la section ci-dessous.
- Division par âge. Diviser, par exemple, en cinq tranches d’âge différentes :
- 0-18 ans
- 18-25 ans
- 25-40 ans
- 40-55 ans
- 55-65 ans
- Division par caractéristique du résultat du test (détermination du niveau d’un résultat donné). L’algorithme vous guide pas à pas jusqu’au dernier niveau, après quoi le résultat final est déterminé et nommé en conséquence.
Les arbres de décision apprennent relativement vite et ne nécessitent pas une grande puissance de calcul. Cependant, pour qu’un algorithme sache comment construire cet arbre automatiquement et puisse « fouiller » les niveaux appropriés, il doit disposer d’une quantité de données suffisamment importante pour que les erreurs soient aussi minimes que possible.
Ces algorithmes sont largement utilisés dans les domaines de la finance, du marketing et du commerce électronique pour l’évaluation de la solvabilité, la segmentation de la clientèle et la recommandation de produits. Par exemple, un arbre de décision peut prédire si un client est solvable en fonction de ses revenus, de son âge et de ses antécédents de crédit ou recommander des produits aux clients en fonction de leurs achats antérieurs.
- Arbre de décision boosté
Cet algorithme est utilisé pour les tâches de classification et de régression. Il utilise le concept d’apprentissage d’ensemble, où plusieurs algorithmes d’apprentissage faibles (tels que des arbres de décision peu profonds avec seulement quelques niveaux) sont combinés pour créer une prédiction plus précise. L’amplification progressive permet de construire des modèles prédictifs de manière séquentielle, où chaque arbre vise à prédire l’erreur laissée par l’arbre précédent ; cela crée une séquence d’arbres. Le résultat est un algorithme très précis qui nécessite néanmoins beaucoup de mémoire.
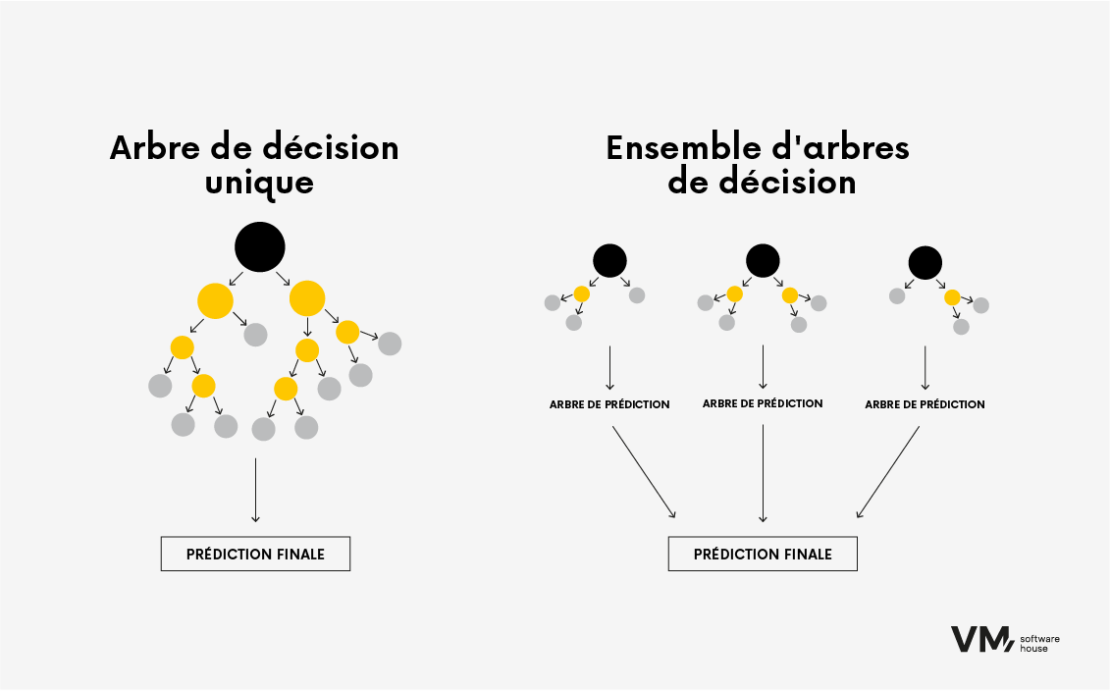
L’arbre de décision boosté est, par exemple, utilisé dans les banques d’investissement ou pour les systèmes d’évaluation du risque de crédit, c’est-à-dire lorsque la précision est importante, que les ressources ne sont pas limitées ou que l’algorithme n’a pas besoin d’être mis à jour fréquemment.
- Forêt aléatoire
L’algorithme Random Forest est une technique populaire d’apprentissage automatique utilisée pour les tâches de classification et de régression. Cette technique appartient aux méthodes d’apprentissage ensembliste, dans lesquelles plusieurs arbres de décision sont construits pendant la formation et combinés pour obtenir une prédiction plus précise et plus stable.
C’est comme si l’on réunissait un groupe d’experts divers travaillant ensemble pour prendre une décision. Chaque modèle apporte sa contribution et, ensemble, ils obtiennent de meilleures performances que n’importe quel modèle isolé. Le principal avantage des forêts aléatoires est que le modèle est plus précis qu’un arbre de décision, car plus la source d’information est diversifiée, plus la forêt aléatoire est robuste, puisqu’une seule source de données anormale ne l’influencera pas.
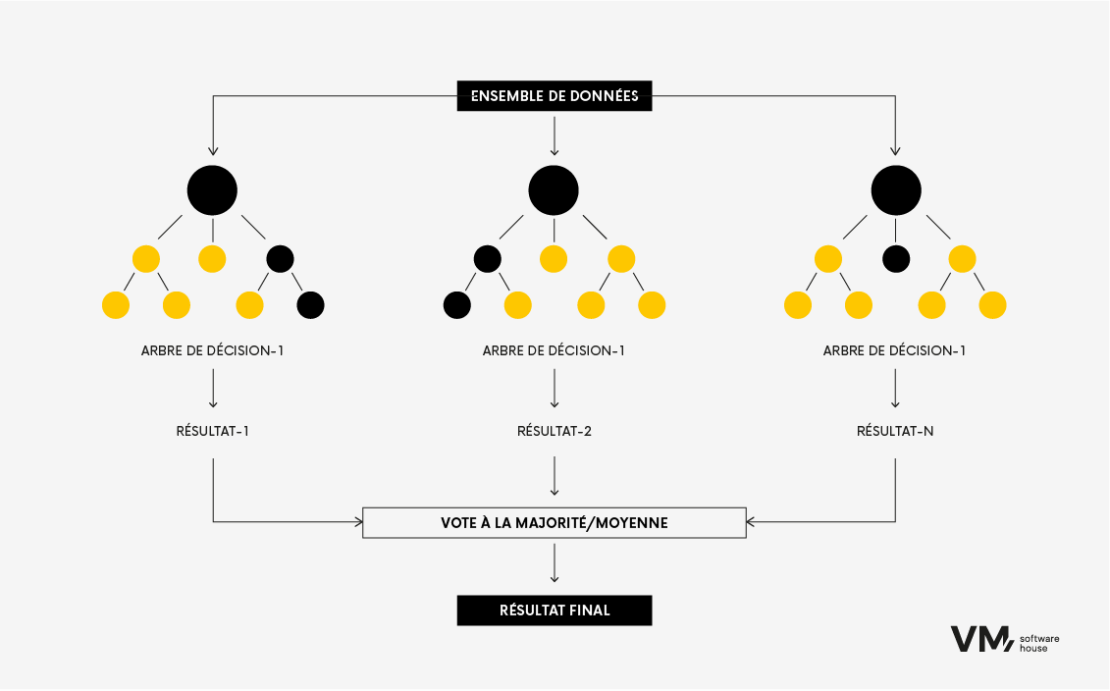
L’inconvénient de cette méthode est qu’elle nécessite de grandes ressources de données, ce qui la rend couteuse en termes de calcul. Elle est le plus souvent utilisée dans les banques d’investissement ou les systèmes d’évaluation du risque de crédit.
- Réseaux neuronaux
Il s’agit de l’un des algorithmes les plus sophistiqués que nous présentons dans cet article. Il s’inspire du fonctionnement du cerveau humain, imitant les processus par lesquels les neurones biologiques travaillent ensemble pour identifier les phénomènes, peser les options et tirer des conclusions.

Les réseaux neuronaux sont construits à partir de cellules cérébrales artificielles appelées unités. Ces unités travaillent ensemble pour apprendre, reconnaitre des modèles et prendre des décisions, comme le fait le cerveau humain. Le fonctionnement des réseaux neuronaux peut être comparé à la combinaison de la puissance d’un ordinateur et de cellules cérébrales densément connectées.
Mode opératoire
Les ordinateurs utilisent des transistors, de petits dispositifs de commutation. Les microprocesseurs modernes contiennent plus de 50 milliards de transistors, mais ils sont connectés en chaines sérielles relativement simples. Les transistors sont connectés dans des circuits de base appelés portes logiques. Les réseaux neuronaux imitent les connexions des vrais neurones en connectant des cellules cérébrales artificielles (unités) en couches.
Cette méthode est le plus souvent utilisée pour des problèmes complexes avec de grands ensembles de données, dans des problèmes où il est difficile de voir des modèles simples. Son principal avantage est qu’elle permet d’apprendre des modèles complexes et qu’elle est adaptée aux tâches d’apprentissage en profondeur. En revanche, elle nécessite d’importantes ressources informatiques (GPU) et un grand nombre de données d’apprentissage.
Les réseaux neuronaux sont utilisés dans différents domaines :
- Reconnaissance d’images : Identification et recherche d’objets dans les images.
- Traitement du langage naturel : Comprendre et générer le langage humain.
- Systèmes de recommandation : Suggestions personnalisées (par exemple, recommandations Netflix).
- Diagnostic médical : Détection de maladies à partir d’images médicales.
- Prévisions financières : Tendances des marchés boursiers, évaluation du risque de crédit, etc.
L’avenir de l’analyse prédictive
Les modèles d’analyse prédictive jouent un rôle essentiel dans le domaine des prévisions, car en analysant de grandes quantités de données historiques, les organisations peuvent prédire les performances futures avec un degré élevé de précision.
Elles constituent également la base de la prise de décision stratégique et de l’optimisation opérationnelle dans tous les secteurs. Qu’il s’agisse de rationaliser les inspections sanitaires des restaurants, de résoudre des problèmes commerciaux complexes ou d’ajuster les stratégies de marketing, la capacité de prédire les performances futures marque une avancée considérable dans la manière dont les données stimulent le progrès et l’innovation.
En mettant en œuvre des algorithmes d’apprentissage automatique, vous pouvez faire des prédictions précises sur la base de nouvelles données inédites. Il est important d’itérer régulièrement et d’affiner le processus en fonction des exigences spécifiques d’un projet. Si vous souhaitez en discuter avec des spécialistes de l’IA/ML, n’hésitez pas à nous contacter.
Dans cet article, nous nous concentrerons sur les algorithmes de ML de base. Nous discuterons de leurs types, de leur fonctionnement et des étapes nécessaires à la création et à l’entrainement de vos propres modèles.
Qu’est-ce qu’un algorithme d’apprentissage automatique ?
Les algorithmes d’apprentissage automatique sont des modèles mathématiques formés à partir de données. Ils utilisent des techniques statistiques et d’analyse prédictive dans l’analyse des données pour apprendre des modèles et des relations entre les données. Ils utilisent ensuite ces connaissances pour faire des prédictions ou prendre des mesures sur des données nouvelles et non testées.
Leur principal avantage réside dans leur capacité à traiter les données d’entrainement sous de nouvelles formes, inconnues auparavant, ce qui leur permet de faire des prédictions précises dans des scénarios réels.
Critères de sélection des algorithmes
Le choix d’un algorithme dépend de nombreuses variables. Même les data scientists les plus expérimentés ne peuvent pas déterminer le meilleur algorithme avant de l’avoir testé sur un ensemble de données précises.
Par conséquent, le choix relève largement de la spéculation si l’on ne teste pas d’abord plusieurs algorithmes sur un ensemble défini de données. Toutefois, il existe un ensemble de règles qui, sur la base de plusieurs variables, vous aident à restreindre votre recherche aux 2 ou 3 algorithmes les mieux adaptés à votre cas particulier. Vous pouvez tester les algorithmes indiqués sur un ensemble de données réelles afin que la prise de décision soit une formalité.
- Type de tâche
Nous ajustons généralement les méthodes, en commençant par les plus simples, pour confirmer qu’il est judicieux de passer à des algorithmes plus profonds et plus complexes. Tout d’abord, nous analysons le type de tâche sur lequel nous travaillons ; par exemple, s’agit-il d’une tâche de classification dans laquelle nous voulons prédire des catégories spécifiques ? Ou s’agit-il d’une tâche de régression dans laquelle on veut prédire des valeurs continues ? Mieux nous comprenons la nature de la tâche, plus le choix d’un algorithme spécifique sera précis.
- Taille et type de données
La compréhension des données est la clé du succès. C’est pourquoi nous analysons toujours les données spécifiques que nous traitons ; les bonnes données fournissent les informations dont nous avons besoin. L’analyse exploratoire des données est toujours la première étape d’un projet.
La compréhension des données est également utile aux étapes intermédiaires :
– Avant de procéder au nettoyage des données, nous collectons des informations sur les valeurs manquantes.
– Avant de commencer à transformer les données, nous devons savoir quel type de variables se trouve dans l’ensemble.
– Avant de commencer le processus de modélisation, nous vérifions les observations aberrantes et les variables ayant des distributions inhabituelles dans l’ensemble.
Règles de modélisation des données
Certains algorithmes sont mieux adaptés aux petits ensembles de données, tandis que d’autres peuvent traiter efficacement de grands ensembles de données et des relations complexes entre les variables.
Si vous disposez d’un petit ensemble de données avec une relation simple entre les variables, des algorithmes tels que la régression linéaire ou la régression logistique peuvent être suffisants. Si vous disposez d’un vaste ensemble de données avec des relations complexes, des algorithmes tels que les forêts aléatoires ou les machines à vecteurs de support peuvent être plus appropriés.
- Interprétation ou performance
Un autre facteur à prendre en compte est le compromis entre l’interprétabilité et l’efficacité. Certains algorithmes, tels que les arbres de décision, permettent l’interprétation et fournissent des explications claires sur leurs prédictions. D’autres algorithmes, tels que les réseaux neuronaux, peuvent être plus performants, mais manquent d’interprétabilité.
Si l’interprétabilité est essentielle à votre projet, les algorithmes tels que les arbres de décision ou la régression logistique sont de bons choix. Si la performance est l’objectif principal et que l’interprétabilité n’est pas une priorité, les réseaux neuronaux ou les modèles d’apprentissage profond peuvent être plus appropriés.
- La complexité de l’algorithme
La complexité de l’algorithme est également un facteur essentiel. Certains algorithmes sont relativement simples et faciles à mettre en œuvre, tandis que d’autres sont plus complexes et nécessitent des compétences de programmation ou des ressources informatiques avancées.
Si vos compétences en programmation sont limitées, des algorithmes tels que la régression linéaire ou les arbres de décision constituent un bon point de départ. Si vous disposez de compétences en programmation et de ressources informatiques plus avancées, vous pouvez explorer des algorithmes plus complexes, tels que les réseaux neuronaux ou les modèles DL.
Compte tenu de ces facteurs, vous pouvez réduire vos options et choisir l’algorithme d’apprentissage automatique qui convient à votre projet. Il est important d’expérimenter différents algorithmes et d’évaluer leurs performances pour votre tâche et vos données précises.
Division des algorithmes dans l’apprentissage automatique
La manière la plus générale de diviser les algorithmes est basée sur le type d’apprentissage : supervisé et non supervisé.
Apprentissage supervisé
Les algorithmes d’apprentissage supervisé sont formés sur des données étiquetées, où les données d’entrée sont associées à la sortie correcte ou à la variable cible. L’algorithme apprend à affecter les données d’entrée aux données de sortie appropriées en trouvant des modèles et des relations dans les données. Ce type d’algorithme est couramment utilisé dans des tâches telles que la classification et la régression.
Nous utilisons des algorithmes, par exemple la régression, pour prédire une valeur numérique sur la base des caractéristiques de sortie. Cette valeur peut être, par exemple, la solvabilité estimée, le risque de fraude pour une transaction sélectionnée ou une valeur binaire indiquant si un client bancaire donné sera un bon ou un mauvais emprunteur. En résumé, dans ce cas, nous savons exactement ce que nous recherchons et sur quoi nous baserons nos décisions.
Un exemple serait un ensemble de données sur les clients d’une banque, décrit par des variables telles que la date de naissance, le numéro d’identification, le solde du compte, l’adresse du domicile, les données sur les antécédents de crédit, l’historique des transactions, etc.
Apprentissage non supervisé
Les algorithmes d’apprentissage non supervisé sont formés sur des données non étiquetées, dans lesquelles seules les données d’entrée sont disponibles sans étiquette de sortie ou de cible correspondante. L’objectif de l’apprentissage non supervisé est de découvrir des modèles ou des structures cachés dans les données. Les algorithmes d’apprentissage non supervisé sont utiles lorsque la structure sous-jacente des données est inconnue.
Nous utilisons souvent des algorithmes de ce type dans des tâches telles que le regroupement et la réduction de la dimensionnalité. Par exemple, l’algorithme regroupe des points de données similaires dans les tâches de regroupement en fonction de leurs similitudes internes. Cela peut être utile dans des tâches telles que la segmentation de la clientèle, où l’algorithme peut identifier des groupes de clients ayant des préférences ou des comportements similaires.
Algorithmes populaires d’apprentissage automatique
Les algorithmes d’apprentissage automatique se présentent sous de nombreuses formes et formats, chacun ayant des caractéristiques uniques. Dans cette section, nous examinerons quelques algorithmes populaires et leurs applications dans divers secteurs.
- Classification binaire
Dans les tâches de classification, l’algorithme apprend à classer les données d’entrée dans deux catégories ou classes prédéfinies.
La classification est utilisée dans des situations telles que la détection d’objets, toutes sortes d’automatisation, le comptage d’objets, mais aussi, par exemple, dans le domaine médical, comme la détection de divers changements dans l’imagerie médicale, par exemple, lorsque nous voulons distinguer une personne malade d’une personne en bonne santé.
La classification binaire implique la formation d’un algorithme pour affecter les données d’entrée à deux catégories ou classes prédéterminées. Par exemple, un algorithme d’apprentissage supervisé peut être entrainé à déterminer si un courriel est un pourriel ou non en analysant un ensemble de données de courriels étiquetés. La classification binaire est couramment utilisée lorsqu’il s’agit de passer au crible un ensemble de données donné et de séparer deux groupes.
À quelles questions les algorithmes de classification répondent-ils ? Par exemple :
- Le client sera-t-il un bon emprunteur ? (remboursera-t-il le prêt en totalité, sans retard significatif ?) | 0,1 (oui ou non).
- Un client donné voudra-t-il annuler nos services ? | Le taux de résiliation est de 0,1 (oui ou non).
- La transaction est-elle frauduleuse ? | 0,1 (oui ou non).
- Classification multiclasses
La classification multiclasses consiste à essayer de prédire un résultat unique, comme dans la classification binaire, mais avec plus de deux classes. Parfois, nous voulons différencier quelque chose d’un peu plus compliqué. Dans le cas de la distinction des maladies, par exemple, nous voulons savoir de quel grade de cancer il s’agit, à quel stade il se trouve, ou déterminer un type spécifique de cancer parmi d’autres types.
Dans l’image ci-dessus, nous voyons l’application d’algorithmes sous supervision. Les méthodes utilisées sont les suivantes :
- CLASSIFICATION – à l’aide de la classification, nous pouvons dire que dans l’image, il y a un chien, des jouets en peluche et une tasse.
- DÉCOUVERTE D’OBJET – nous voulons trouver une tasse particulière pour un chien. Grâce à cette méthode, nous déterminerons les limites de l’objet (rectangle) et la probabilité que cet objet spécifique se trouve dans le cadre.
- SEGMENTATION – une méthode qui tente de trouver et de marquer des objets individuels aussi précisément que possible, en les séparant les uns des autres. SEGMENTATION SÉMANTIQUE – une méthode qui marque un objet des objets du même type.
- Régression linéaire
La régression linéaire est une équation linéaire qui détermine la relation entre différentes dimensions.
L’algorithme apprend à trouver la ligne la mieux ajustée qui minimise la somme des erreurs quadratiques entre les valeurs prédites et les valeurs réelles. Il est souvent utilisé dans la prédiction numérique. Par exemple, un algorithme qui peut prédire la valeur d’une maison en fonction de caractéristiques telles que son emplacement, le nombre de chambres et la superficie.
La régression linéaire est largement utilisée en finance, en économie et en sciences sociales pour analyser les relations entre les variables et faire des prédictions. Par exemple, elle peut être utilisée pour prédire les prix des actions sur la base de données historiques.
- Régression logistique
La régression logistique est un algorithme populaire permettant de prédire un résultat binaire, tel que « oui » ou « non », sur la base d’observations précédentes de l’ensemble des données.
Détermine la relation entre une variable dépendante binaire et une ou plusieurs variables indépendantes en ajustant une fonction logistique aux données. L’algorithme apprend à trouver la courbe la mieux adaptée qui sépare deux classes.
La régression logistique est largement utilisée dans les domaines du marketing, de la santé et des sciences sociales pour prédire le taux de désabonnement, détecter les fraudes et diagnostiquer les maladies. Par exemple, elle peut être utilisée pour indiquer si un client est susceptible d’abandonner un achat sur la base de son comportement passé ou pour diagnostiquer si un patient est atteint d’une maladie particulière sur la base de ses symptômes et de ses antécédents médicaux.
- Arbres de décision
Les arbres de décision sont des algorithmes polyvalents qui peuvent être utilisés pour des tâches de classification et de régression. Ils divisent les données en sous-ensembles sur la base des valeurs des caractéristiques d’entrée et effectuent des prédictions en parcourant l’arbre de la racine à la feuille. L’avantage des arbres réside dans l’interprétabilité des résultats de la prédiction.
Exemple :
Vous avez les résultats des tests. Vous voulez en savoir plus :
- Séparation des sexes : femme ou homme ? Êtes-vous une femme ? Consultez la section ci-dessous.
- Division par âge. Diviser, par exemple, en cinq tranches d’âge différentes :
- 0-18 ans
- 18-25 ans
- 25-40 ans
- 40-55 ans
- 55-65 ans
- Division par caractéristique du résultat du test (détermination du niveau d’un résultat donné). L’algorithme vous guide pas à pas jusqu’au dernier niveau, après quoi le résultat final est déterminé et nommé en conséquence.
Les arbres de décision apprennent relativement vite et ne nécessitent pas une grande puissance de calcul. Cependant, pour qu’un algorithme sache comment construire cet arbre automatiquement et puisse « fouiller » les niveaux appropriés, il doit disposer d’une quantité de données suffisamment importante pour que les erreurs soient aussi minimes que possible.
Ces algorithmes sont largement utilisés dans les domaines de la finance, du marketing et du commerce électronique pour l’évaluation de la solvabilité, la segmentation de la clientèle et la recommandation de produits. Par exemple, un arbre de décision peut prédire si un client est solvable en fonction de ses revenus, de son âge et de ses antécédents de crédit ou recommander des produits aux clients en fonction de leurs achats antérieurs.
- Arbre de décision boosté
Cet algorithme est utilisé pour les tâches de classification et de régression. Il utilise le concept d’apprentissage d’ensemble, où plusieurs algorithmes d’apprentissage faibles (tels que des arbres de décision peu profonds avec seulement quelques niveaux) sont combinés pour créer une prédiction plus précise. L’amplification progressive permet de construire des modèles prédictifs de manière séquentielle, où chaque arbre vise à prédire l’erreur laissée par l’arbre précédent ; cela crée une séquence d’arbres. Le résultat est un algorithme très précis qui nécessite néanmoins beaucoup de mémoire.
L’arbre de décision boosté est, par exemple, utilisé dans les banques d’investissement ou pour les systèmes d’évaluation du risque de crédit, c’est-à-dire lorsque la précision est importante, que les ressources ne sont pas limitées ou que l’algorithme n’a pas besoin d’être mis à jour fréquemment.
- Forêt aléatoire
L’algorithme Random Forest est une technique populaire d’apprentissage automatique utilisée pour les tâches de classification et de régression. Cette technique appartient aux méthodes d’apprentissage ensembliste, dans lesquelles plusieurs arbres de décision sont construits pendant la formation et combinés pour obtenir une prédiction plus précise et plus stable.
C’est comme si l’on réunissait un groupe d’experts divers travaillant ensemble pour prendre une décision. Chaque modèle apporte sa contribution et, ensemble, ils obtiennent de meilleures performances que n’importe quel modèle isolé. Le principal avantage des forêts aléatoires est que le modèle est plus précis qu’un arbre de décision, car plus la source d’information est diversifiée, plus la forêt aléatoire est robuste, puisqu’une seule source de données anormale ne l’influencera pas.
L’inconvénient de cette méthode est qu’elle nécessite de grandes ressources de données, ce qui la rend couteuse en termes de calcul. Elle est le plus souvent utilisée dans les banques d’investissement ou les systèmes d’évaluation du risque de crédit.
- Réseaux neuronaux
Il s’agit de l’un des algorithmes les plus sophistiqués que nous présentons dans cet article. Il s’inspire du fonctionnement du cerveau humain, imitant les processus par lesquels les neurones biologiques travaillent ensemble pour identifier les phénomènes, peser les options et tirer des conclusions.
Les réseaux neuronaux sont construits à partir de cellules cérébrales artificielles appelées unités. Ces unités travaillent ensemble pour apprendre, reconnaitre des modèles et prendre des décisions, comme le fait le cerveau humain. Le fonctionnement des réseaux neuronaux peut être comparé à la combinaison de la puissance d’un ordinateur et de cellules cérébrales densément connectées.
Mode opératoire
Les ordinateurs utilisent des transistors, de petits dispositifs de commutation. Les microprocesseurs modernes contiennent plus de 50 milliards de transistors, mais ils sont connectés en chaines sérielles relativement simples. Les transistors sont connectés dans des circuits de base appelés portes logiques. Les réseaux neuronaux imitent les connexions des vrais neurones en connectant des cellules cérébrales artificielles (unités) en couches.
Cette méthode est le plus souvent utilisée pour des problèmes complexes avec de grands ensembles de données, dans des problèmes où il est difficile de voir des modèles simples. Son principal avantage est qu’elle permet d’apprendre des modèles complexes et qu’elle est adaptée aux tâches d’apprentissage en profondeur. En revanche, elle nécessite d’importantes ressources informatiques (GPU) et un grand nombre de données d’apprentissage.
Les réseaux neuronaux sont utilisés dans différents domaines :
- Reconnaissance d’images : Identification et recherche d’objets dans les images.
- Traitement du langage naturel : Comprendre et générer le langage humain.
- Systèmes de recommandation : Suggestions personnalisées (par exemple, recommandations Netflix).
- Diagnostic médical : Détection de maladies à partir d’images médicales.
- Prévisions financières : Tendances des marchés boursiers, évaluation du risque de crédit, etc.
L’avenir de l’analyse prédictive
Les modèles d’analyse prédictive jouent un rôle essentiel dans le domaine des prévisions, car en analysant de grandes quantités de données historiques, les organisations peuvent prédire les performances futures avec un degré élevé de précision.
Elles constituent également la base de la prise de décision stratégique et de l’optimisation opérationnelle dans tous les secteurs. Qu’il s’agisse de rationaliser les inspections sanitaires des restaurants, de résoudre des problèmes commerciaux complexes ou d’ajuster les stratégies de marketing, la capacité de prédire les performances futures marque une avancée considérable dans la manière dont les données stimulent le progrès et l’innovation.
En mettant en œuvre des algorithmes d’apprentissage automatique, vous pouvez faire des prédictions précises sur la base de nouvelles données inédites. Il est important d’itérer régulièrement et d’affiner le processus en fonction des exigences spécifiques d’un projet. Si vous souhaitez en discuter avec des spécialistes de l’IA/ML, n’hésitez pas à nous contacter.